Linux内核中断总结
中断嵌套
早期的内核是可以中断嵌套的,现在不可以。
早期的Linux内核中断分为两种情况:
带IRQF_DISABLED的快中断,这种中断在执行的时候是不允许新的中断触发,也就是不允许嵌套。
不带IRQF_DISABLED的慢中断,这种中断在执行中断处理程序的时候是开中断执行的,是允许更高优先级的中断打断自己,嵌套执行的。
在老版本内核中指定一个中断服务程序不想被打断的方法,就是request_irq的时候添加IRQF_DISABLED标志,如:
request_irq(HD_IRQ, hd_interrupt, IRQF_DISABLED, "hd", NULL)
但这个能力在2010年被这个e58aa3d2d0cc01ad8d6f7f640a0670433f794922提交废除了。
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=e58aa3d2d0cc
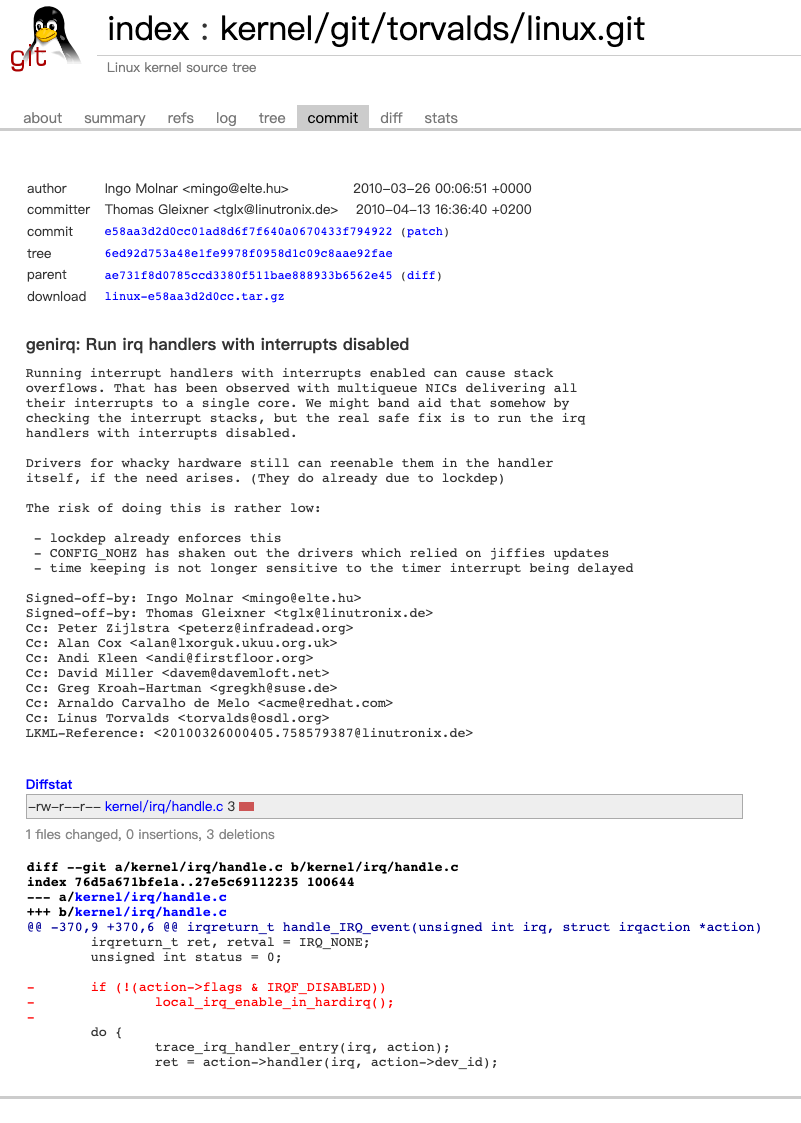
这意味着从这个commit开始,无论设不设置IRQF_DISABLED,内核都不会在中断服务的时候开启CPU对中断的响应。
在2.6.32(2009/12/03)版本内核中还有这段逻辑。
kernel/irq/handle.c
363 /**
364 * handle_IRQ_event - irq action chain handler
365 * @irq: the interrupt number
366 * @action: the interrupt action chain for this irq
367 *
368 * Handles the action chain of an irq event
369 */
370 irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction *action)
371 {
372 irqreturn_t ret, retval = IRQ_NONE;
373 unsigned int status = 0;
374
375 if (!(action->flags & IRQF_DISABLED))
376 local_irq_enable_in_hardirq();
377
378 do {
379 trace_irq_handler_entry(irq, action);
380 ret = action->handler(irq, action->dev_id);
381 trace_irq_handler_exit(irq, action, ret);
382
383 switch (ret) {
384 case IRQ_WAKE_THREAD:
385 /*
386 * Set result to handled so the spurious check
387 * does not trigger.
388 */
389 ret = IRQ_HANDLED;
390
391 /*
392 * Catch drivers which return WAKE_THREAD but
393 * did not set up a thread function
394 */
395 if (unlikely(!action->thread_fn)) {
396 warn_no_thread(irq, action);
397 break;
398 }
399
400 /*
401 * Wake up the handler thread for this
402 * action. In case the thread crashed and was
403 * killed we just pretend that we handled the
404 * interrupt. The hardirq handler above has
405 * disabled the device interrupt, so no irq
406 * storm is lurking.
407 */
408 if (likely(!test_bit(IRQTF_DIED,
409 &action->thread_flags))) {
410 set_bit(IRQTF_RUNTHREAD, &action->thread_flags);
411 wake_up_process(action->thread);
412 }
413
414 /* Fall through to add to randomness */
415 case IRQ_HANDLED:
416 status |= action->flags;
417 break;
418
419 default:
420 break;
421 }
422
423 retval |= ret;
424 action = action->next;
425 } while (action);
426
427 if (status & IRQF_SAMPLE_RANDOM)
428 add_interrupt_randomness(irq);
429 local_irq_disable();
430
431 return retval;
432 }
关于local_irq_enable_in_hardirq的作用就是关闭CPU响应中断。以2.6.32为例其定义如下
include/linux/interrupt.h
182 # define local_irq_enable_in_hardirq() local_irq_enable()
include/linux/irqflags.h
59 #define local_irq_enable() \
60 do { trace_hardirqs_on(); raw_local_irq_enable(); } while (0)
arch/x86/include/asm/irqflags.h
42 static inline void native_irq_enable(void)
43 {
44 asm volatile("sti": : :"memory");
45 }
79 static inline void raw_local_irq_enable(void)
80 {
81 native_irq_enable();
82 }
在2.6.36(2010/10/20)版本的内核中就没有这一段逻辑了。
361 /**
362 * handle_IRQ_event - irq action chain handler
363 * @irq: the interrupt number
364 * @action: the interrupt action chain for this irq
365 *
366 * Handles the action chain of an irq event
367 */
368 irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction *action)
369 {
370 irqreturn_t ret, retval = IRQ_NONE;
371 unsigned int status = 0;
372
373 do {
374 trace_irq_handler_entry(irq, action);
375 ret = action->handler(irq, action->dev_id);
376 trace_irq_handler_exit(irq, action, ret);
377
378 switch (ret) {
379 case IRQ_WAKE_THREAD:
380 /*
381 * Set result to handled so the spurious check
382 * does not trigger.
383 */
384 ret = IRQ_HANDLED;
385
386 /*
387 * Catch drivers which return WAKE_THREAD but
388 * did not set up a thread function
389 */
390 if (unlikely(!action->thread_fn)) {
391 warn_no_thread(irq, action);
392 break;
393 }
394
395 /*
396 * Wake up the handler thread for this
397 * action. In case the thread crashed and was
398 * killed we just pretend that we handled the
399 * interrupt. The hardirq handler above has
400 * disabled the device interrupt, so no irq
401 * storm is lurking.
402 */
403 if (likely(!test_bit(IRQTF_DIED,
404 &action->thread_flags))) {
405 set_bit(IRQTF_RUNTHREAD, &action->thread_flags);
406 wake_up_process(action->thread);
407 }
408
409 /* Fall through to add to randomness */
410 case IRQ_HANDLED:
411 status |= action->flags;
412 break;
413
414 default:
415 break;
416 }
417
418 retval |= ret;
419 action = action->next;
420 } while (action);
421
422 if (status & IRQF_SAMPLE_RANDOM)
423 add_interrupt_randomness(irq);
424 local_irq_disable();
425
426 return retval;
427 }
时钟中断对时间片用尽的处理方式
参考的是2.4.0版本的内核
arch/i386/kernel/time.c
454 /*
455 * This is the same as the above, except we _also_ save the current
456 * Time Stamp Counter value at the time of the timer interrupt, so that
457 * we later on can estimate the time of day more exactly.
458 */
459 static void timer_interrupt(int irq, void *dev_id, struct pt_regs *regs)
460 {
......
501 do_timer_interrupt(irq, NULL, regs);
......
505 }
380 /*
381 * timer_interrupt() needs to keep up the real-time clock,
382 * as well as call the "do_timer()" routine every clocktick
383 */
384 static inline void do_timer_interrupt(int irq, void *dev_id, struct pt_regs *regs)
385 {
......
406 do_timer(regs);
......
450 }
kernel/timer.c
674 void do_timer(struct pt_regs *regs)
675 {
676 (*(unsigned long *)&jiffies)++;
677 #ifndef CONFIG_SMP
678 /* SMP process accounting uses the local APIC timer */
679
680 update_process_times(user_mode(regs));
681 #endif
682 mark_bh(TIMER_BH);
683 if (TQ_ACTIVE(tq_timer))
684 mark_bh(TQUEUE_BH);
685 }
575 /*
576 * Called from the timer interrupt handler to charge one tick to the current
577 * process. user_tick is 1 if the tick is user time, 0 for system.
578 */
579 void update_process_times(int user_tick)
580 {
581 struct task_struct *p = current;
582 int cpu = smp_processor_id(), system = user_tick ^ 1;
583
584 update_one_process(p, user_tick, system, cpu);
585 if (p->pid) {
586 if (--p->counter <= 0) {
587 p->counter = 0;
588 p->need_resched = 1;
589 }
590 if (p->nice > 0)
591 kstat.per_cpu_nice[cpu] += user_tick;
592 else
593 kstat.per_cpu_user[cpu] += user_tick;
594 kstat.per_cpu_system[cpu] += system;
595 } else if (local_bh_count(cpu) || local_irq_count(cpu) > 1)
596 kstat.per_cpu_system[cpu] += system;
597 }
在时钟中断处理函数timer_interrupt中调用do_timer_interrupt再调用到do_timer最终调用到update_process_times,在该函数中会将当前进程的时间片减1,如果发现当前进程时间片用尽,则将其need_resched标记置1。need_resched定义在task_struct里,可以看到其位置在第20字节处(mm_segment_t为4字节)。
include/asm-i386/processor.h
323 typedef struct {
324 unsigned long seg;
325 } mm_segment_t;
include/linux/sched.h
277 struct task_struct {
278 /*
279 * offsets of these are hardcoded elsewhere - touch with care
280 */
281 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
282 unsigned long flags; /* per process flags, defined below */
283 int sigpending;
284 mm_segment_t addr_limit; /* thread address space:
285 0-0xBFFFFFFF for user-thead
286 0-0xFFFFFFFF for kernel-thread
287 */
288 struct exec_domain *exec_domain;
289 volatile long need_resched;
290 unsigned long ptrace;
291
292 int lock_depth; /* Lock depth */
293
294 /*
295 * offset 32 begins here on 32-bit platforms. We keep
296 * all fields in a single cacheline that are needed for
297 * the goodness() loop in schedule().
298 */
299 long counter;
300 long nice;
301 unsigned long policy;
在从内核返回到用户空间前,会判断need_resched这个值,如果被置1,则会在ret_with_reschedule时调用reschedule最终会调用到schedule。
71 /*
72 * these are offsets into the task-struct.
73 */
74 state = 0
75 flags = 4
76 sigpending = 8
77 addr_limit = 12
78 exec_domain = 16
79 need_resched = 20
80 tsk_ptrace = 24
81 processor = 52
188 /*
189 * Return to user mode is not as complex as all this looks,
190 * but we want the default path for a system call return to
191 * go as quickly as possible which is why some of this is
192 * less clear than it otherwise should be.
193 */
194
195 ENTRY(system_call)
196 pushl %eax # save orig_eax
197 SAVE_ALL
198 GET_CURRENT(%ebx)
199 cmpl $(NR_syscalls),%eax
200 jae badsys
201 testb $0x02,tsk_ptrace(%ebx) # PT_TRACESYS
202 jne tracesys
203 call *SYMBOL_NAME(sys_call_table)(,%eax,4)
204 movl %eax,EAX(%esp) # save the return value
205 ENTRY(ret_from_sys_call)
206 #ifdef CONFIG_SMP
207 movl processor(%ebx),%eax
208 shll $CONFIG_X86_L1_CACHE_SHIFT,%eax
209 movl SYMBOL_NAME(irq_stat)(,%eax),%ecx # softirq_active
210 testl SYMBOL_NAME(irq_stat)+4(,%eax),%ecx # softirq_mask
211 #else
212 movl SYMBOL_NAME(irq_stat),%ecx # softirq_active
213 testl SYMBOL_NAME(irq_stat)+4,%ecx # softirq_mask
214 #endif
215 jne handle_softirq
216
217 ret_with_reschedule:
218 cmpl $0,need_resched(%ebx)
219 jne reschedule
220 cmpl $0,sigpending(%ebx)
221 jne signal_return
222 restore_all:
223 RESTORE_ALL
287 reschedule:
288 call SYMBOL_NAME(schedule) # test
289 jmp ret_from_sys_call
need_resched就是在schedule里被清零的。而counter也会在这里被重新填值。
498 /*
499 * 'schedule()' is the scheduler function. It's a very simple and nice
500 * scheduler: it's not perfect, but certainly works for most things.
501 *
502 * The goto is "interesting".
503 *
504 * NOTE!! Task 0 is the 'idle' task, which gets called when no other
505 * tasks can run. It can not be killed, and it cannot sleep. The 'state'
506 * information in task[0] is never used.
507 */
508 asmlinkage void schedule(void)
509 {
510 struct schedule_data * sched_data;
511 struct task_struct *prev, *next, *p;
512 struct list_head *tmp;
......
517 prev = current;
......
542
543 switch (prev->state) {
544 case TASK_INTERRUPTIBLE:
545 if (signal_pending(prev)) {
546 prev->state = TASK_RUNNING;
547 break;
548 }
549 default:
550 del_from_runqueue(prev);
551 case TASK_RUNNING:
552 }
553 prev->need_resched = 0;
......
656 return;
657
658 recalculate:
659 {
660 struct task_struct *p;
661 spin_unlock_irq(&runqueue_lock);
662 read_lock(&tasklist_lock);
663 for_each_task(p)
664 p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
665 read_unlock(&tasklist_lock);
666 spin_lock_irq(&runqueue_lock);
667 }
668 goto repeat_schedule;
669
670 still_running:
671 c = goodness(prev, this_cpu, prev->active_mm);
672 next = prev;
673 goto still_running_back;
674
675 handle_softirq:
676 do_softirq();
677 goto handle_softirq_back;
678
679 move_rr_last:
680 if (!prev->counter) {
681 prev->counter = NICE_TO_TICKS(prev->nice);
682 move_last_runqueue(prev);
683 }
684 goto move_rr_back;
685
686 scheduling_in_interrupt:
687 printk("Scheduling in interrupt\n");
688 BUG();
689 return;
690 }
这里还有一点需要特别解释一下,就是为什么在update_process_times里586行处对时间片减1后,判断是否用尽的判断方法是if (--p->counter <= 0)而不是if (--p->counter == 0) ?
因为可能出现如下的执行序列,前一个时钟中断在将counter减到0后,开始中断底半部处理工作,其处理耗时可能会比较长,甚至长过一个时钟中断周期,而底半处理又是在开中断的情况下执行的,因此有可能前一个时钟中断还没执行到重新调度逻辑(在这个逻辑里会重置need_resched和counter),又一次时钟中断发生,而这次时钟中中断必然会将counter从0减到负数.